신입 프로그래머 기술 면접준비
- 6 mins인공지능
인공지능은 본인의 자소서 기반 꼬리물기 질문에 대비하여 작성
Data Set 준비
train data 70%, test data 30%로 나누는 것이 일반적이며 학습과정중 중단지점을 위해 validation set을 할당하기도 한다.
test와 validation은 반드시 unseen 해야한다.
K-fold cross validation
Data가 적을때 자주 사용하는 방식으로 Data Set을 k등분하여 k개 모델을 학습하는데 각 등분별 validation data로 두어 모델을 평가하고 평균내어 해당 모델이 어느 정도의 성능을 보일것이라 판단후 최종적으로 전체의 데이터를 train data로 이용하여 모델을 만든다.
데이터 불균형
class별 균등하게 데이터가 존재해야하는데 불균형할 경우 모델의 성능평가가 무의미 하다.
ROC커브
모델에 대한 성능 평가로 밑넓이가 넓을수록 성능이 좋다.
목적함수
회귀 : 평균오차법, 1/2 시그마 (실제-판단)^2
분류 : 크로스 엔트로피, 라벨별 log를 취한 소프트맥스 값의 합
1인라벨 * log(해당 라벨의 소프트맥스값) + 0인라벨 * (1-log(해당 라벨의 소프트맥스값))
softmax
e^(해당 라벨 output값) / 전체 e^(output 값) 합, 확률값이라 생각
(항상 0~1사이)
앙상블 분류기
배깅 : 여러학습데이터(복원추출)을 준비하여 각 다른 모델을 학습후 결과를 하나로
부스팅 : 1개의 학습데이터에 대해 학습후 오분류 데이터에 대하여 가중치를 두어 다시 학습하는 방식
KNN(k-nearest neighbor)
새로운 데이터에 대하여 output을 결정하는 방식으로 새로운 데이터가 주어질때 인접한 k개의 label을 확인후 다수인 class의 output으로 결정한다.
clustering
유사한 데이터끼리 모으는 방식을 말하며 k개의 무작위 중심좌표를 결정후에 기존 데이터를 재군집화 한다. 군집된 데이터에서 각각 중심좌표를 재결정, 중심좌표를 이동한다. 이러한 행위를 각 군집의 분산의 합이 최소가 될때까지 진행한다.
딥러닝 흐름, 왜 딥러닝이 핫해 졌는가?
(or 해당 활성화 함수 등이 사용되는 이유)
- 퍼셉트론(선형결합)으로 인해 and나 or게이트가 가능하였으나 xor같은 문제는 해결못함
- 다층 퍼셉트론으로 인해 xor문제해결 가능하나 활성화 함수로 계단함수가 사용되어 자동으로 가중치를 학습못함(미분불가)
- 계단함수와 비슷한 모양인 sigmoid함수로 미분이 가능하여 학습이 가능하나 sigmoid의 도함수가 0~1사이 이므로 역전파시 기울기가 소멸되어 층을 깊게 쌓을수 없음.
- 활성화 함수로 relu를 사용하여 층을 깊게 쌓을수 있음.
오버피팅 방지하는 방법
- 규제화 : 목적함수에 모델의 복잡도(가중치의합)를 추가하여 학습한다.
- 드롭아웃 : 순전파시 일정 확률로 특정 노드를 꺼 데이터가 전이되는것을 막는다.
- 미니배치 : 1epoch을 등분할때 등분된것을 mini-batch라 말하며 mini-batch의 평균 gradient를 이용해 가중치를 조절하므로 둔감하다.
gradient 방식
대표적으로 일반적인 경사하강법과 모멘텀을 고려한 경사하강법으로 나뉘어지며 모멘텀을 고려한 경사하강법은 기존의 기울기 벡터와 현재 기울기 벡터의 합으로 가중치를 갱신한다.
학습율, adaGrad
가중치별로 별도의 학습율을 적용한다, 많이 변화한 가중치는 낮은 학습율 적용
ADAM
모멘텀 + ada
운영체제
프로세스와 쓰레드의 차이
가장 큰 차이는 자원할당 유무에 있다. 추가적인 프로세스를 위해선 리소스를 할당 받아야 하며 쓰레드 경우 새로운 자원할당을 받지않고 리소스 자원을 공유하며 병렬적으로 실행되는 독립적 단위이다. 이로인해 context swtiching 오버헤드에 있어 쓰레드가 유리하다.
Context Switching이란?
현재 진행중인 task(프로세스, 쓰레드)의 상태를 저장하고 다음 진행할 task 상태를 읽는과정
어떻게 저장?
레지스터에 저장하고 PCB(process control block)로 관리됨
PCB엔 어떤게 저장되나?
프로세스의 상태, 다음 실행될 명령어의 주소값, 스케쥴링 우선순위 등이 저장되어있다.
메모리상 프로세스
스택(지역)/ -> <-/ 힙(동적할당)/ 데이터(전역)/ 텍스트(컴파일된 코드)
동기화란?
멀티프로세서에서 자원에 대해 독점적인 접근을 할 수 있도록 하는 방식. 멀티 프로세스는 세마포를 사용한다.
Critical Section이란?
공유 데이터로 인해 원자 단위로 실행될 필요가 있는 구역.
어찌해결?
동기화를 통해 Critical Section에 lock을 걸어 하나의 프로세스가 자원을 독점하게한다.
교착상태란?
두 프로세스가 자원에 대해 lock이 걸려있는데 그 lock을 풀어주는게 서로 가지고 있어 무한정 기다리는 상황을 말한다.
발생조건은?
- 상호배제 : 자원은 한번에 한프로세스만 사용
- 점유대기 : 자원, 다른 프로세스 사용시 대기가 존재한다.
- 비선점 : 다른 프로세스가 점유한 데이터는 끝날때까지 뺏을 수 없다.
- 순환대기 : p0가 p1을 기다리고 p1이 p2를 기다리고..
예방법-> 발생조건중 하나제거
뮤텍스와 세마포 차이
뮤텍스: 한 쓰레드, 프로세스에 의해 소유될 수 있는 Key🔑를 기반으로 한 상호배제기법
세마포어: 현재 공유자원에 접근할 수 있는 쓰레드, 프로세스의 수를 나타내는 값을 두어 상호배제를 달성하는 기법
예를 들어 뮤텍스는 한개의 화장실(공유자원)에 대해 한사람(프로세스)이 들어가 있으면 화장실줄(대기열큐)에서 기다려야하며 세마포어는 n개의 화장실에대해 생각하면된다.
페이지와 세그멘테이션 차이
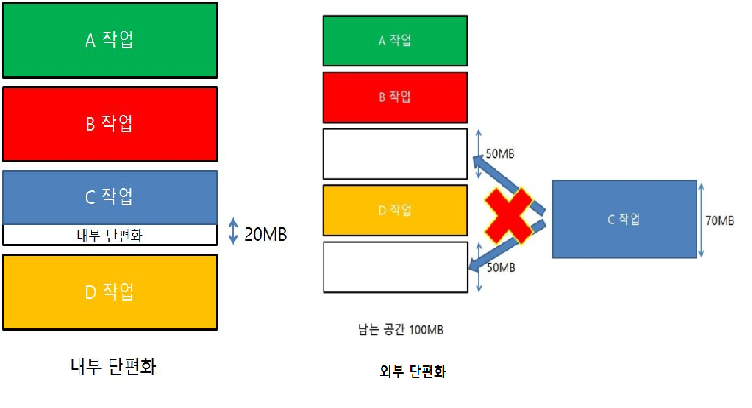
둘다 가상메모리 관리 기법이며 페이징의 경우 프로세스를 같은 크기 블럭인 페이지로 나누며 물리메모리의 프레임 단위에 공간이 남아 내부단편화가 발생할 수 있으며
세그멘테이션의 경우 프로세스를 서로 다른 크기로 나누며 프레임 단위가 작아 할당을 못하는 외부단편화가 발생할수있다
네트워크
OSI-7 layer
App : 사용자가 네트워크에 접근할 수 있도록 서비스 제공, message 표현계층 : 세션 계층간 인터페이스를 일관성있게 제공. 세션계층 : 사용자간 통신 연결을 유지 및 설정한다. Transport : 프로세스간 통신지원, segment, port# Network : 종단간 통신지원, datagram, IP datalink : 인접노드간 통신지원, Mac address physical : 비트전송
app 계층 가능구조
- client-server간 통신 대표적으로 HTTP가 있으며 이는 TCP서비스를 요구한다 비지속 연결 : 1개의 객체만 보내고 연결을 끊음 지속 연결 : time out시 까지 연결을 지속한다.
TCP와 UDP의 차이
TCP는 연결 지향형이며 오류제어, 흐름제어, 혼잡제어를(window size를 이용하여) 제공한다
UDP의 경우 비연결 지향이며 최소의 비트오류(체크섬)을 제어한다.
3way-handshaking 이란?
TCP 연결과정으로 클라이언트가 서버에 접속요청 SYN패킷 보냄.
이에대하여 서버는 ACK와 SYN을 보냄.
클라이언트는 두 패킷을 받고 다시 ACK를 보내면서 연결이 성립
GET과 POST의 차이?
GET은 헤더에 URI가 필요하며 길이가 제한적이며 그대로 노출된다.
POST의 경우 바디에 데이터를 넣어 전달가능하며 데이터 크기를 크게 할수있고 보안적으로 낫다.
프로그래밍
객체지향이란?
필요한 데이터와 로직을 객체로 추상화하여 각기 다른 역할을 가진 객체들로 프로그램을 만드는것이다.
이점?
유지보수, 재사용에 유리하다. 클래스 : 설계도, 객체 : 설계도 대로 만들어진것. 상속: 객체를 확장하고, 다형적(같은 종의 생물이지만 특징이 고유한)이점을 이용한것이다.
추상클래스와 인터페이스 차이
클래스에게 구현을 강제화 하는 공통점이있으나 추상클래스의 경우 만들어야할 여러 클래스들의 공통점을 추상화시켜 만든것이며 상속의 개념이며(이미 정의된 메소드와 멤버변수) 선언만된 메소드의 구현이 필요 인터페이스경우 선언된 메소드만 존재하며 상속개념보단 동일한 동작을 위한 구현을 강제화 하는것.
+) 선언된 메소드 이용 -> 객체가 같은 동작을 다르게 행하는것을 위해 예를 들어 동물들은 걷지만 누구는 네발 누구는 두발..
c언어와 C++의 차이
C언어는 절차지향이며 C++은 객체지향이다.
절차지향경우 컴퓨터의 작업처리방식과 유사하기 때문에 실행속도가 빠르지만 유지보수가 힘들다
객체지향의경우 캡슐화(class), 상속, 다형성(하나의 이름으로 다양한 상황에 대처)의 특징으로 유지보수, 재사용이 용이하지만 절차언어에 비해 설계에 많은시간이 필요하며 느리다.
class와 구조체의 차이
구조체는 변수들의 집합이며 class는 데이터와 로직을 추상화한것을 말한다.
스크립트와 컴파일 언어의 차이
컴파일러의 유무이며 컴파일언어 경우 수정시 다시 컴파일을 해야지 수정적용되지만 스크립트 언어경우 바로 해석 한다.
call by reference VS call by value
레퍼런스는 매개변수로 주소값을 전달하는 방식이며 밸류경우 값을 복사하는것을 말한다.
오버로딩과 오버라이딩 차이
오버로딩의 경우 같은 이름의 메소드를 매개변수 타입이나 개수등의 차이를 둬 재정의하는것이며
오버라이딩의 경우 상속에서 부모 메소드를 재정의하는것을 말한다
접근제한자
- public : 접근에 제한없음.
- protected : 자손 클래스에서 접근가능.
- private : 같은 패키지 내에서만 접근가능
포인터에 대해 설명
포인터는 메모리 주소를 저장하는 변수이다.
c++의 iteration의 역할
반복자는(Iterator)는 포인터와 유사한 객체로서 STL컨테이너에 저장된 객체들의 시퀀스를 순회 할 때 사용한다.
큐와 스택의 차이
동작원리에 차이가 있다. 스택의 경우 LIFO이며 큐의경우 FIFO이다.
단순 연결리스트란?
배열의 크기를 벡터처러 가변적으로 사용할 수 있는것. 구조체에 변수의값과 다음 노드의 주소를 담는다.
정렬
선택정렬
각 자리별 가장 작은 수를 차근히 자리매김(교환), O(n^2)
삽입정렬
idx를 두번째 원소부터 시작하며 idx인 수가 왼쪽(이미 정렬된) 어디에 들어가야하는지 정해서 삽입한다. 정렬된경우 O(n), 그외 O(n^2)
버블정렬
앞에서부터 쌍끼리 비교하며 교환하는데, n번 반복한다
머지소트
크기를 반씩 쪼개어 쪼개진 두 arr를 합병한다.
퀵정렬
피봇(기준)으로 그보다 작은거는 왼쪽 큰거는 오른쪽으로 옮기는것 파티션 나뉘어진거에서 또다시 한 파티션 정해 피봇설정 원소 좌우로 나눈다. 최악의 경우 O(n^2)(피봇이 계속 작은경우만 잡히는경우) 보통 O(nlogN)
BST(Binary Search Tree)
루트 보다 작은값은 왼쪽, 큰값은 오른쪽으로 저장하는 구조로 높이가 logn이 되므로 탐색시간이 O(logN)이다 삭제시 두개의 자식트리가 있는경우 오른쪽 서브트리의 가장작은값(맨왼쪽끝)을 채워둠
전위 후위 중위
후위를 통해 맨 마지막이 최상위 루트인것을 알수있음